Executive Summary
Research on program comprehension has a fundamental limitation: program comprehension is a cognitive process that cannot be directly observed, which leaves considerable room for misinterpretation, uncertainty, and confounders. In Brains On Code, we are developing a neuroscientific foundation of program comprehension. Instead of merely observing whether there is a difference regarding program comprehension (e.g., between two programming methods), we aim at precisely and reliably determining the key factors that cause the difference. This is especially challenging as humans are the subjects of study, and inter-personal variance and other confounding factors obfuscate the results.
The key idea of Brains On Code is to leverage established methods from cognitive neuroscience to obtain insights into the underlying processes and influential factors of program comprehension. Brains On Code pursues a multimodal approach that integrates different neuro-physiological measures as well as a cognitive computational modeling approach to establish the theoretical foundation. This way, Brains On Code lays the foundations of measuring and modeling program comprehension and offers substantial feedback for programming methodology, language design, and education. With Brains On Code, addressing longstanding foundational questions such as "How can we reliably measure program comprehension?", "What makes a program hard to understand?", and "What skills should programmers have?" comes into reach. Brains On Code does not only help answer these questions, but also provides an outline for applying the methodology beyond program code (models, specifications, requirements, etc.).
Overview and Contributions
By employing neuro-physiological measures, Brains On Code connect for the first time all three areas involved in the act of program comprehension, as illustrated in the figure below: (a) the programmer solving a program comprehension task, (b) neuro-physiological correlates of program comprehension, and (c) external observables of program comprehension. It is the gap between the programmer and task (a), on the one hand, and external observables of program comprehension (c), on the other hand, that makes developing models and theories of program comprehension difficult.
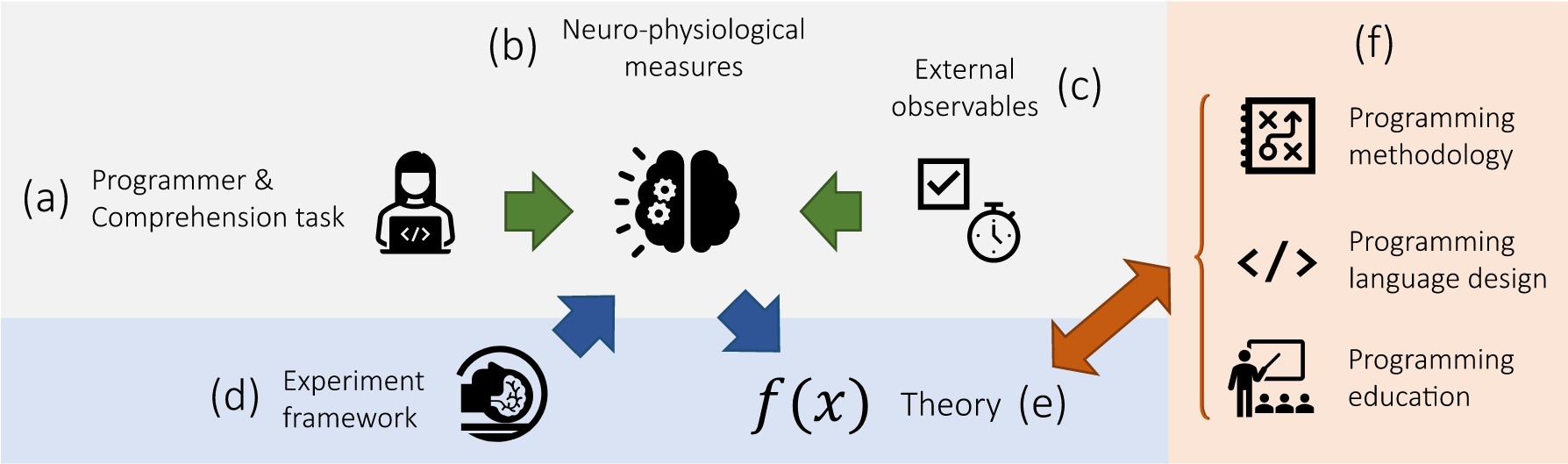
The background is that simple correlations or regression models (e.g., relating the complexity of a program's code and the time to determining the program's output) are often dominated by the inherent complexities of human behavior and of the code as well as by the many factors that may influence the relation, such as inter-task and inter-personal variance, programming expertise, and the use of programming language features and idioms. This leads to a combinatorial explosion of factors that potentially influence program comprehension (individually and in combination). Understanding or even only covering this search space systematically has proved very difficult in the past. Brains On Code's methodological and theoretical contributions bridges this gap and guides us through this search space.
Overall, Brains On Code makes three key contributions:
- A multimodal experiment framework for measuring program comprehension with neuro-physiological
measurment methods (d). - A theoretical foundation of program comprehension based on cognitive theory and architecture (e).
- Answers to foundational questions of programming methodology, language design, and education
enabled by the theoretical and methodological foundation developed in Brains On Code (f).



Brains On Code by Example
To illustrate how we are working in Brains On Code, we discuss how we answer a simple examplary research question.

The research question we would like to answer in this example is whether the use of meaningful identifiers (e.g., for variables and functions) facilitates program comprehension. A common approach is to compare two groups of programmers, one solving a comprehension task (e.g., determining the output) on a program with meaningful identifiers and one without. Say we find that the group working with meaningful identifiers is faster, on average. The problem is that it is still unclear whether this effect is due to the kind of identifiers or something else (different levels of programming experience, etc.). The sheer number of factors that potentially influence program comprehension (individually and in combination) as well as generally small sample sizes (human participants) prevent us from separating effects from confounders. In Brains On Code, we address this problem using neuro-physiological and behavioral measures establishing a reliable relation between treatments (meaningful or not) and external observables (faster or slower).
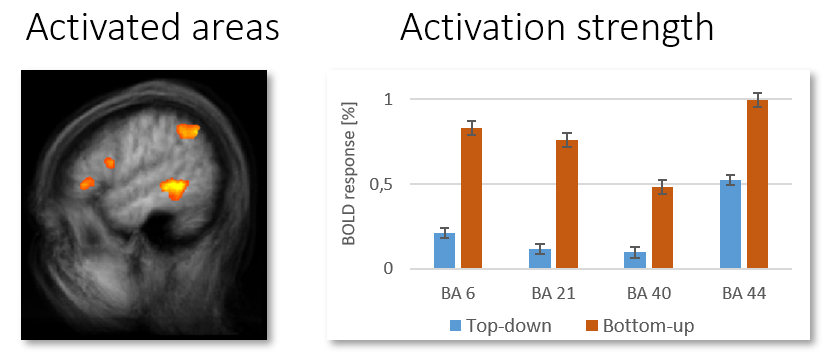
Let us assume that, in an fMRI session, we find that programmers working with meaningful identifiers show a significantly lower neural activation in brain areas related to program comprehension than the other programmers. This gives a first hint that meaningful identifiers reduce cognitive load. Still, is it really the identifiers that cause this reduction? We could ask the programmers, but many cognitive processes take place subconsciously. This is where Brains On Code's multimodal approach comes into play.
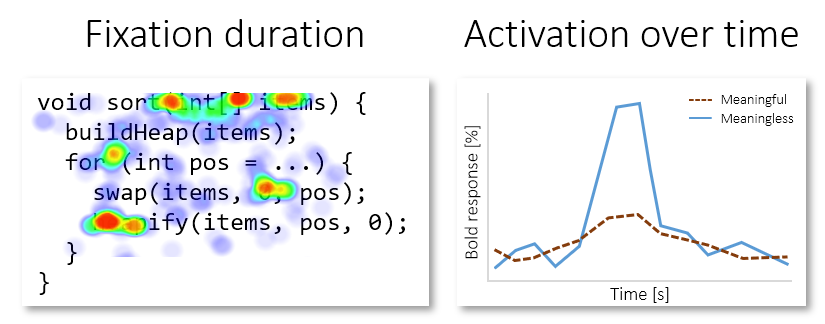
Combining fMRI with eye tracking can shed light on this issue: If the difference in brain activation can be mapped to gaze behavior related to identifiers (e.g., fixation time), this would indicate that the choice of the identifiers is the cause of the difference. In a recent study, we indeed could establish this relation.
Once this result is established, we need to revisit our theoretical understanding of program comprehension. We might introduce the choice of semantic cues (e.g., in the form of meaningful identifiers) as factor that reduces cognitive load and task completion time. The goal is a cognitive model that allows us to run simulations and compare the simulation results with empirical observations. This will raise new issues (e.g., on the influence of type information), which will lead to refined research questions and experiment designs, closing Brains On Code’s feedback loop.
Publications
2026
-
 Marvin Wyrich, Norman Peitek, Kallistos
Weis, and Sven Apel.
Harnessing
Hype to Teach Empirical Thinking: An Experience With AI Coding
Assistants.
In Proceedings of the ACM International Conference on the Foundations of
Software Engineering – Software Engineering Education Track (FSE-SEET). ACM, July 2026.
to appear.
Marvin Wyrich, Norman Peitek, Kallistos
Weis, and Sven Apel.
Harnessing
Hype to Teach Empirical Thinking: An Experience With AI Coding
Assistants.
In Proceedings of the ACM International Conference on the Foundations of
Software Engineering – Software Engineering Education Track (FSE-SEET). ACM, July 2026.
to appear.
- Annabelle Bergum, Anna-Maria Maurer,
Norman Peitek, Regine Bader, Axel Mecklinger, Vera Demberg, Janet Siegmund,
and Sven Apel.
Fixation-related
Potentials Reveal that Confusing Program Code Elicits a Late Frontal
Positivity.
Scientific Reports, Volume 16, page 16833, June
2026.
- Nils Alznauer, Norman Peitek, Youssef
Abdelsalam, Annabelle Bergum, Marvin Wyrich, and Sven Apel.
Eye-Tracking
Insights into the Effects of Type Annotations and Identifier Naming.
In Proceedings of the International Conference on Program Comprehension
(ICPC). ACM, April 2026.
Acceptance rate: 28% (35 / 123); to appear.
- Youssef Abdelsalam, Norman Peitek,
Anna-Maria Maurer, Mariya Toneva, and Sven Apel.
Are
Humans and LLMs Confused by the Same Code? An Empirical Study on
Fixation-Related Potentials and LLM Perplexity.
In Proceedings of the International Conference on Software Engineering
(ICSE). ACM, April 2026.
Acceptance rate: 21% (320 / 1469); to appear.
- Alina Mailach, Janet Siegmund, Sven
Apel, and Norbert Siegmund.
Views
on Internal and External Validity in Empirical Software Engineering: 10 Years
Later and Beyond.
In Proceedings of the International Conference on Software Engineering
(ICSE). ACM, April 2026.
Acceptance rate: 21% (320 / 1469); to appear.
- Youssef Abdelsalam, Norman Peitek,
Annabelle Bergum, and Sven Apel.
The
Effect of Comments on Program Comprehension: An Eye-Tracking Study.
Empirical Software Engineering (EMSE), 31(4):94, March
2026.
- Annabelle Bergum, Norman Peitek,
Maurice Rekrut, Janet Siegmund, and Sven Apel.
On
the Influence of the Baseline in Neuroimaging Experiments on Program
Comprehension.
ACM Transactions on Software Engineering and Methodology (TOSEM), 35(3):83, February
2026.
2025
- Marvin Wyrich, Johannes C. Hofmeister,
Sven Apel, and Janet Siegmund.
Object
Disorientation.
IEEE Software, 42(6):81–88, November 2025.
- Alisa
Welter, Niklas Schneider, Tobias Dick, Kallistos Weis, Christof Tinnes,
Marvin Wyrich, and Sven Apel.
An
Empirical Study of Knowledge Transfer in AI Pair Programming.
In Proceedings of the International Conference on Automated Software
Engineering (ASE), pages 166–177. IEEE, November 2025.
Acceptance rate: 22% (245 / 1136).
- Marvin Wyrich, Christof Tinnes,
Sebastian Baltes, and Sven Apel.
The
Silent Scientist: When Software Research Fails to Reach Its Audience.
Communications of the ACM (CACM), 68(11):24–27, October
2025.
- Max
Weber, Alina Mailach, Sven Apel, Janet Siegmund, Raimund Dachselt, and
Norbert Siegmund.
Understanding
Debugging as Episodes: A Case Study on Performance Bugs in Configurable
Software Systems.
In Proceedings of the ACM on Software Engineering, Volume 2, Issue: ACM
International Conference on the Foundations of Software Engineering (FSE), pages 1409–1431. ACM, June 2025.
Acceptance rate: 22% (135 / 612).
- Ruchit Rawal, Victor-Alexandru
Pădurean, Sven Apel, Adish Singla, and Mariya Toneva.
Hints Help Finding and Fixing Bugs
Differently in Python and Text-based Program Representations.
In Proceedings of the International Conference on Software Engineering
(ICSE), pages 1230–1242. IEEE, April 2025.
Acceptance rate: 21% (245 / 1150).
2024
- Timon Dörzapf, Norman Peitek,
Marvin Wyrich, and Sven Apel.
Data
Analysis Tools Affect Outcomes of Eye-Tracking Studies.
In Proceedings of the International Symposium on Empirical Software
Engineering and Measurement (ESEM), pages 96–106. ACM,
October 2024.
Acceptance rate: 24% (34 / 139).
- Marvin Wyrich and Sven Apel.
Evidence
Tetris in the Pixelated World of Validity Threats.
In Proceedings of the 1st IEEE/ACM International Workshop on
Methodological Issues with Empirical Studies in Software Engineering (WSESE), pages 13–16. ACM, April
2024.
2022
- Norman Peitek, Annabelle Bergum,
Maurice Rekrut, Jonas Mucke, Matthias Nadig, Chris Parnin, Janet Siegmund,
and Sven Apel.
Correlates
of Programmer Efficacy and their Link to Experience: A Combined EEG and
Eye-Tracking Study.
In Proceedings of the ACM Joint European Software Engineering Conference
and Symposium on the Foundations of Software Engineering (ESEC/FSE), pages 120–131. ACM, November 2022.
Acceptance rate: 22% (99 / 449).
Team
Project Members





Long-Term Collaborators



Acknowledgements
We gratefully acknowledge the support of the European Research Council for funding Brains On Code with an ERC Advanced Grant!

The project is carried out by the Chair of Software Engineering at Saarland University & Saarland Informatics Campus.
Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency. Neither the European Union nor the granting authority can be held responsible for them.